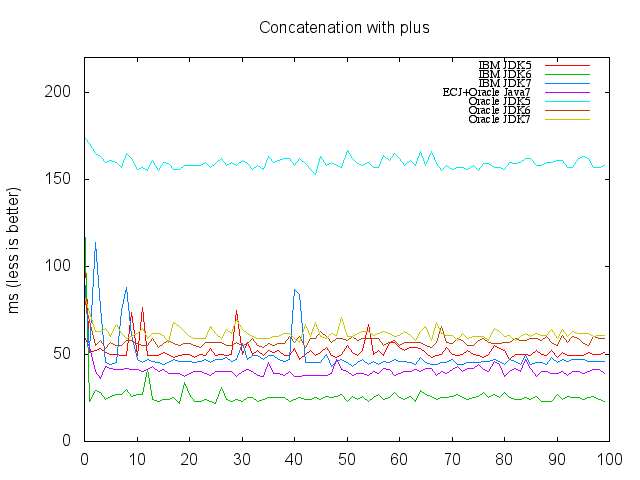
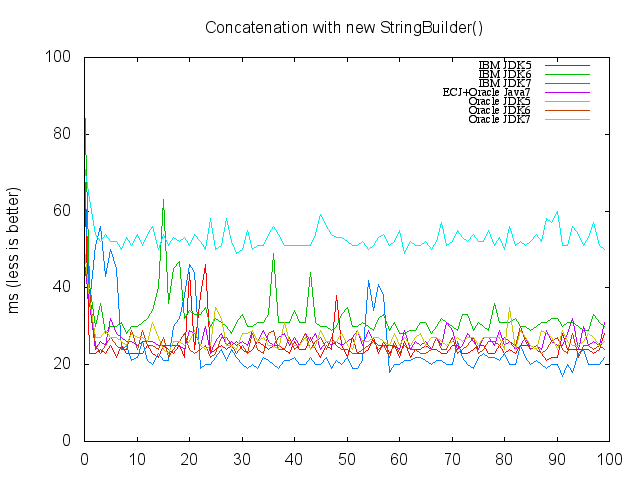
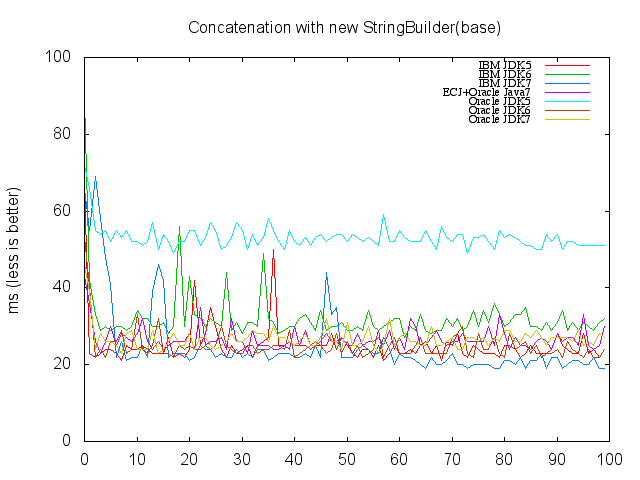
Spring Data Neo4j is the project within Spring Data project which provides an extension to the Spring programming model for writing applications that uses Neo4j as graph database. To write tests using NoSQLUnit for Spring Data Neo4j applications, you do need nothing special apart from considering that Spring Data Neo4j uses a special property called type in graph nodes and relationships which stores the fully qualified classname of that entity.
Apart from type property at node/relationship level, we also need to create one index for nodes and one index for relationships. In case of nodes, types index name is required, meanwhile rel_types is required for relationships. In both cases we must set key value to className and value to full qualified classname.
Type mapping
IndexingNodeTypeRepresentationStrategy and IndexingRelationshipTypeRepresentationStrategy are used as default type mapping implementation, but you can also use SubReferenceNodeTypeRepresentationStrategy which stores entity types in a tree in the graph representing the type and interface hierarchy, or you can customize even more by implementing NodeTypeRepresentationStrategy interface.
Hands on Work
Application
Starfleet has asked us to develop an application for storing all starfleet members, with their relationship with other starfleet members, and the ship where they serve. The best way to implement this requirement is using Neo4j database as backend system. Moreover Spring Data Neo4j is used at persistence layer. This application is modelized into two Java classes, one for members and another one for starships. Note that for this example there are no properties in relationships, so only nodes are modelized.
Member class
@NodeEntitypublic class Member { private static final String COMMANDS = "COMMANDS"; @GraphId Long nodeId; private String name; private Starship assignedStarship; public Member() { super(); } public Member(String name) { this.name = name; } @Fetch @RelatedTo(type=COMMANDS, direction=Direction.OUTGOING) private Set<Member> commands; public void command(Member member) { this.commands.add(member); } public Set<Member> commands() { return this.commands; } public Starship getAssignedStarship() { return assignedStarship; } public String getName() { return name; } public void assignedIn(Starship starship) { this.assignedStarship = starship; } //Equals and Hash methods} Starship class
@NodeEntitypublic class Starship { private static final String ASSIGNED = "assignedStarship"; @GraphId Long nodeId; private String starship; public Starship() { super(); } public Starship(String starship) { this.starship = starship; } @RelatedTo(type = ASSIGNED, direction=Direction.INCOMING) private Set<Member> crew; public String getStarship() { return starship; } public void setStarship(String starship) { this.starship = starship; } //Equals and Hash methods} Apart from model classes, we also need two repositories for implementing CRUD operations, and spring context xml file. Spring Data Neo4j uses Spring Data Commons infrastructure allowing us to create interface based compositions of repositories, providing default implementations for certain operations.
MemberRepository class
public interface MemberRepository extends GraphRepository<Member>, RelationshipOperationsRepository<Member> { Member findByName(String name);} See that apart from operations provided by GrapRepository interface like save, findAll, findById, … we are defining one query method too called findByName. Spring Data Neo4j repositories (and most of Spring Data projects) provide a mechanism to define queries using the known Ruby on Rails approach for defining finder queries.
StarshipRepository class
public interface StarshipRepository extends GraphRepository<Starship>, RelationshipOperationsRepository<Starship> {} application-context file
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:neo4j="http://www.springframework.org/schema/data/neo4j" xsi:schemaLocation="http://www.springframework.org/schema/beanshttp://www.springframework.org/schema/beans/spring-beans-3.1.xsdhttp://www.springframework.org/schema/contexthttp://www.springframework.org/schema/context/spring-context-3.1.xsdhttp://www.springframework.org/schema/data/neo4j http://www.springframework.org/schema/data/neo4j/spring-neo4j.xsd"> <context:component-scan base-package="com.lordofthejars.nosqlunit.springdata.neo4j"/> <context:annotation-config/> <neo4j:repositories base-package="com.lordofthejars.nosqlunit.springdata.repository"/></beans>
Testing
Unit Testing
As it has been told previously, for writing datasets for Spring Data Neo4j, we don’t have to do anything special beyond creating node and relationship properties correctly and defining the required indexes. Let’s see the dataset used to test the findByName method by seeding
Neo4j database.
star-trek-TNG-dataset.xml file
<?xml version="1.0" ?><graphml xmlns="http://graphml.graphdrawing.org/xmlns" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://graphml.graphdrawing.org/xmlns http://graphml.graphdrawing.org/xmlns/1.0/graphml.xsd"> <key id="name" for="node" attr.name="name" attr.type="string"></key> <key id="__type__" for="node" attr.name="__type__" attr.type="string"></key> <key id="starship" for="node" attr.name="starship" attr.type="string"></key> <graph id="G" edgedefault="directed"> <node id="3"> <data key="__type__">com.lordofthejars.nosqlunit.springdata.neo4j.Member</data> <data key="name">Jean-Luc Picard</data> <index name="__types__" key="className">com.lordofthejars.nosqlunit.springdata.neo4j.Member</index> </node> <node id="1"> <data key="__type__">com.lordofthejars.nosqlunit.springdata.neo4j.Member</data> <data key="name">William Riker</data> <index name="__types__" key="className">com.lordofthejars.nosqlunit.springdata.neo4j.Member</index> </node> <node id="4"> <data key="__type__">com.lordofthejars.nosqlunit.springdata.neo4j.Starship</data> <data key="starship">NCC-1701-E</data> <index name="__types__" key="className">com.lordofthejars.nosqlunit.springdata.neo4j.Starship</index> </node> <edge id="11" source="3" target="4" label="assignedStarship"></edge> <edge id="12" source="1" target="4" label="assignedStarship"></edge> <edge id="13" source="3" target="1" label="COMMANDS"></edge> </graph></graphml>
See that each node has at least one type property with full qualified classname and an index with name types, key className and full qualified classname as value. Next step is configuring application context for unit tests. application-context-embedded-neo4j.xml
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:neo4j="http://www.springframework.org/schema/data/neo4j" xsi:schemaLocation="http://www.springframework.org/schema/beanshttp://www.springframework.org/schema/beans/spring-beans-3.1.xsdhttp://www.springframework.org/schema/contexthttp://www.springframework.org/schema/context/spring-context-3.1.xsdhttp://www.springframework.org/schema/data/neo4j http://www.springframework.org/schema/data/neo4j/spring-neo4j.xsd"> <import resource="classpath:com/lordofthejars/nosqlunit/springdata/neo4j/application-context.xml"/> <neo4j:config storeDirectory="target/config-test"/></beans>
Notice that we are using Neo4j namespace for instantiating an embedded Neo4j database. And now we can write the JUnit test case: WhenInformationAboutAMemberIsRequired
@RunWith(SpringJUnit4ClassRunner.class)@ContextConfiguration("application-context-embedded-neo4j.xml")public class WhenInformationAboutAMemberIsRequired { @Autowired private MemberRepository memberRepository; @Autowired private StarshipRepository starshipRepository; @Autowired private ApplicationContext applicationContext; @Rule public Neo4jRule neo4jRule = newNeo4jRule() .defaultSpringGraphDatabaseServiceNeo4j(); @Test @UsingDataSet(locations = "star-trek-TNG-dataset.xml", loadStrategy = LoadStrategyEnum.CLEAN_INSERT) public void information_about_starship_where_serves_and_members_under_his_service_should_be_retrieved() { Member jeanLuc = memberRepository.findByName("Jean-Luc Picard"); assertThat(jeanLuc, is(createMember("Jean-Luc Picard"))); assertThat(jeanLuc.commands(), containsInAnyOrder(createMember("William Riker"))); Starship starship = starshipRepository.findOne(jeanLuc.getAssignedStarship().nodeId); assertThat(starship, is(createStarship("NCC-1701-E"))); } private Object createStarship(String starship) { return new Starship(starship); } private static Member createMember(String memberName) { return new Member(memberName); }} There are some important points in the previous class to take under consideration:
- Recall that we need to use Spring
ApplicationContext object to retrieve embedded Neo4j instance defined into Spring application context. - Since lifecycle of database is managed by Spring Data container, there is no need to define any NoSQLUnit lifecycle manager.
Integration Test
Unit tests are usually run against embedded in-memory instances, but in production environment you may require access to external Neo4j servers by using Rest connection, or in case of Spring Data Neo4j instantiating SpringRestGraphDatabase class. You need to write tests to validate that your application still works when you integrate your code with a remote server, and this tests are typically known as integration tests. To write integration tests for our application is as easy as defining an application context with SpringRestGraphDatabase and allow NoSQLUnit to control the lifecycle of Neo4j database.
.application-context-managed-neo4j.xml
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:neo4j="http://www.springframework.org/schema/data/neo4j" xsi:schemaLocation="http://www.springframework.org/schema/beanshttp://www.springframework.org/schema/beans/spring-beans-3.1.xsdhttp://www.springframework.org/schema/contexthttp://www.springframework.org/schema/context/spring-context-3.1.xsdhttp://www.springframework.org/schema/data/neo4j http://www.springframework.org/schema/data/neo4j/spring-neo4j.xsd"> <import resource="classpath:com/lordofthejars/nosqlunit/springdata/neo4j/application-context.xml"/> <bean id="graphDatabaseService" class="org.springframework.data.neo4j.rest.SpringRestGraphDatabase"> <constructor-arg index="0" value="http://localhost:7474/db/data"></constructor-arg> </bean> <neo4j:config graphDatabaseService="graphDatabaseService"/></beans>
Note how instead of registering an embedded instance, we are configuring SpringRestGraphDatabase class to connect to localhost server. And let’s implement an integration test which verifies that all starships can be retrieved from Neo4j server.
WhenInformationAboutAMemberIsRequired
@RunWith(SpringJUnit4ClassRunner.class)@ContextConfiguration("application-context-managed-neo4j.xml")public class WhenInformationAboutStarshipsAreRequired { @ClassRule public static ManagedNeoServer managedNeoServer = newManagedNeo4jServerRule() .neo4jPath( "/Users/alexsotobueno/Applications/neo4j-community-1.7.2") .build(); @Autowired private StarshipRepository starshipRepository; @Autowired private ApplicationContext applicationContext; @Rule public Neo4jRule neo4jRule = newNeo4jRule() .defaultSpringGraphDatabaseServiceNeo4j(); @Test @UsingDataSet(locations = "star-trek-TNG-dataset.xml", loadStrategy = LoadStrategyEnum.CLEAN_INSERT) public void information_about_starship_where_serves_and_members_under_his_service_should_be_retrieved() { EndResult<Starship> allStarship = starshipRepository.findAll(); assertThat(allStarship, containsInAnyOrder(createStarship("NCC-1701-E"))); } private Object createStarship(String starship) { return new Starship(starship); }} Because defaultSpringGraphDatabaseServiceNeo4j method returns a GraphDatabaseService instance defined into application context, in our case it will return the defined SpringRestGraphDatabase instance.
Conclusions
There is not much difference between writing tests for none Spring Data Neo4j applications than the ones they use it. Only keep in mind to define correctly the type property and create required indexes. Also see that from the point of view of NoSQLUnit there is no difference between writing unit or integration tests, apart of lifecycle management of the database engine. Download Code
Reference: Testing Spring Data Neo4j Applications with NoSQLUnit from our JCG partner Alex Soto at the One Jar To Rule Them All blog.
Source : feedproxy[dot]google[dot]com